About me
Greetings! I am Liu Haolin. I was having my Ph.D from the Chinese University of HongKong, Shenzhen from 2019~2024 , under the supervision of Prof. Shuguang Cui and Prof. Xiaoguang Han.
I was an intern in Tencent AI Lab during 2024.
Currently I am a research scientist in Tencent Hunyuan 3D team.
My current research focus are indoor scene reconstruction, understanding, and 3D generative model.
News
- [2025.03] One paper accepted by CVPR 2025!
- [2025.01] Hunyuan3D-2 is now released! feel free to try out and give us feedback.
- [2024.07] MVImgNet 2.0 and GarVerseLOD got accepted as ACM TOG 2024.
- [2023.12] Our latest work LASA is now released!
- [2023.03] MVImgNet got accepted by CVPR 2023.
- [2022.05] InstPIFu got accepted by ECCV 2022.
- [2021.03] Refer-it-in-RGBD got accepted by CVPR 2021.
- [2020.06] JAFPro got accepted by ACM MM 2020.
Publication
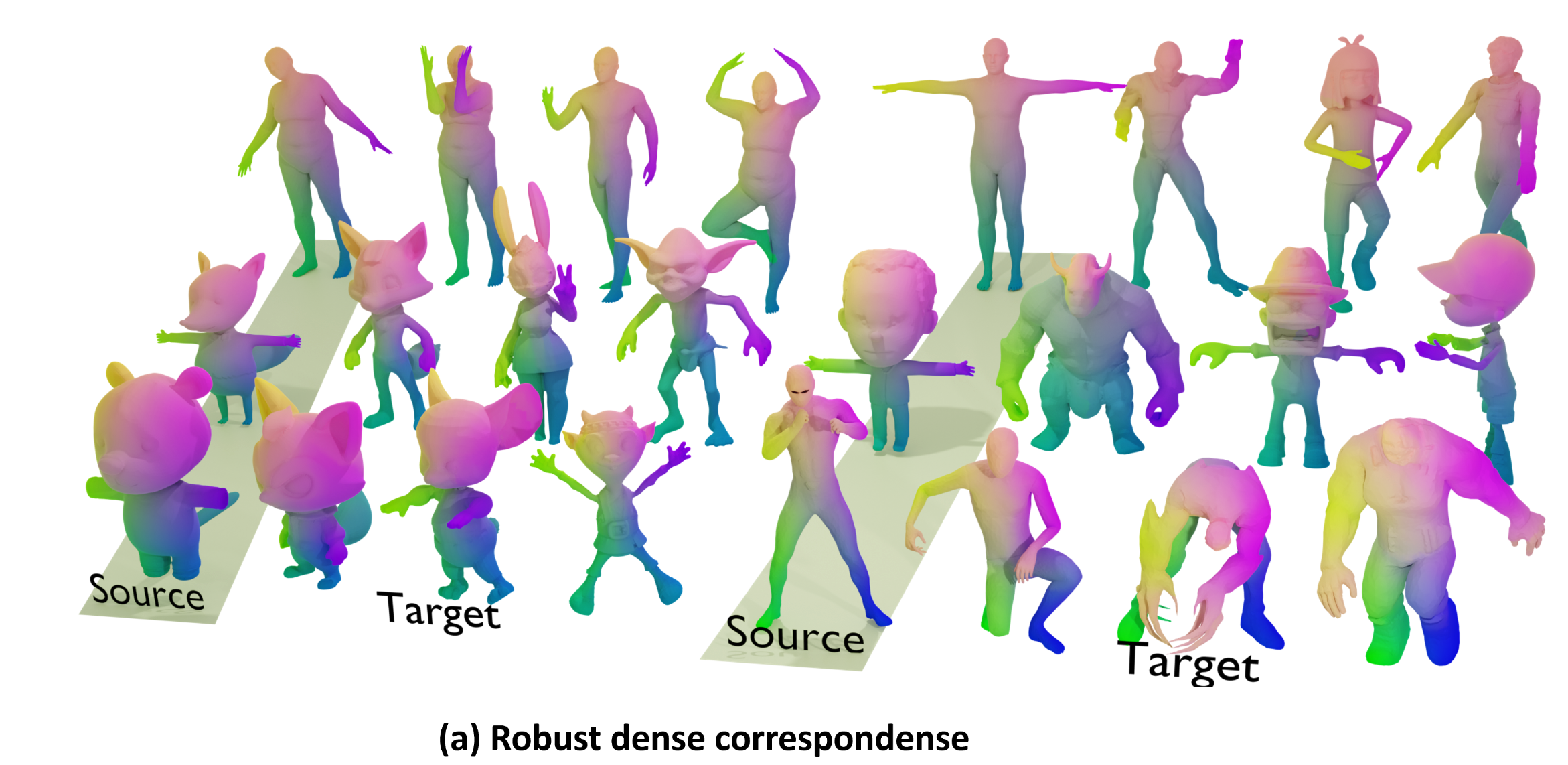

Stable-SCore: A Stable Registration-based Framework for 3D Shape Correspondence
Haolin Liu*, Xiaohang Zhan*, Zizheng Yan*, Zhongjin Luo, Yuxin Wen, Xiaoguang Han†
Computer Vision and Pattern Recognition Conference (CVPR), 2025
paper and codes coming soon

Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Haolin Liu is one of the core contributors
Technical Report, 2025
[paper] [code]

MVImgNet2.0: A Larger-scale Dataset of Multi-view Images
Xiaoguang Han†, Yushuang Wu*, Luyue Shi*, Haolin Liu*, Hongjie Liao, Lingteng Qiu, Weihao Yuan, Xiaodong Gu, Zilong Dong, Shuguang Cui,
ACM Transactions on Graphics (TOG), 2024
[paper]

GarVerseLOD: High-Fidelity 3D Garment Reconstruction from a Single In-the-Wild Image using a Dataset with Levels of Details
Zhongjin Luo, Haolin Liu, Chenghong Li, Wanghao Du, Zirong Jin, Wanhu Sun, Yinyu Nie, Weikai Chen, Xiaoguang Han†,
ACM Transactions on Graphics (TOG), 2024
[paper]

LASA: Instance Reconstruction from Real Scans using A Large-scale Aligned Shape Annotation Dataset
Haolin Liu*, Chongjie Ye*, Yinyu Nie, Yingfan He, Xiaoguang Han†
Computer Vision and Pattern Recognition Conference (CVPR), 2024
[paper] / [project] / [code]

MVImgNet: A Large-scale Dataset of Multi-view Images
Xianggang Yu*, Mutian Xu*, Yidan Zhang*, Haolin Liu*, Chongjie Ye*, Yushuang Wu, Zizheng Yan, Chenming Zhu, Zhangyang Xiong, Tianyou Liang, Guanying Chen, Shuguang Cui, Xiaoguang Han†
Computer Vision and Pattern Recognition Conference (CVPR), 2023
[paper] / [project] / [code]

Towards High-Fidelity Single-view Holistic Reconstruction of Indoor Scenes
Haolin Liu*, Yujian Zheng*, Guanying Chen, Shuguang Cui, Xiaoguang Han†
European Conference on Computer Vision (ECCV), 2022
[paper] / [code]
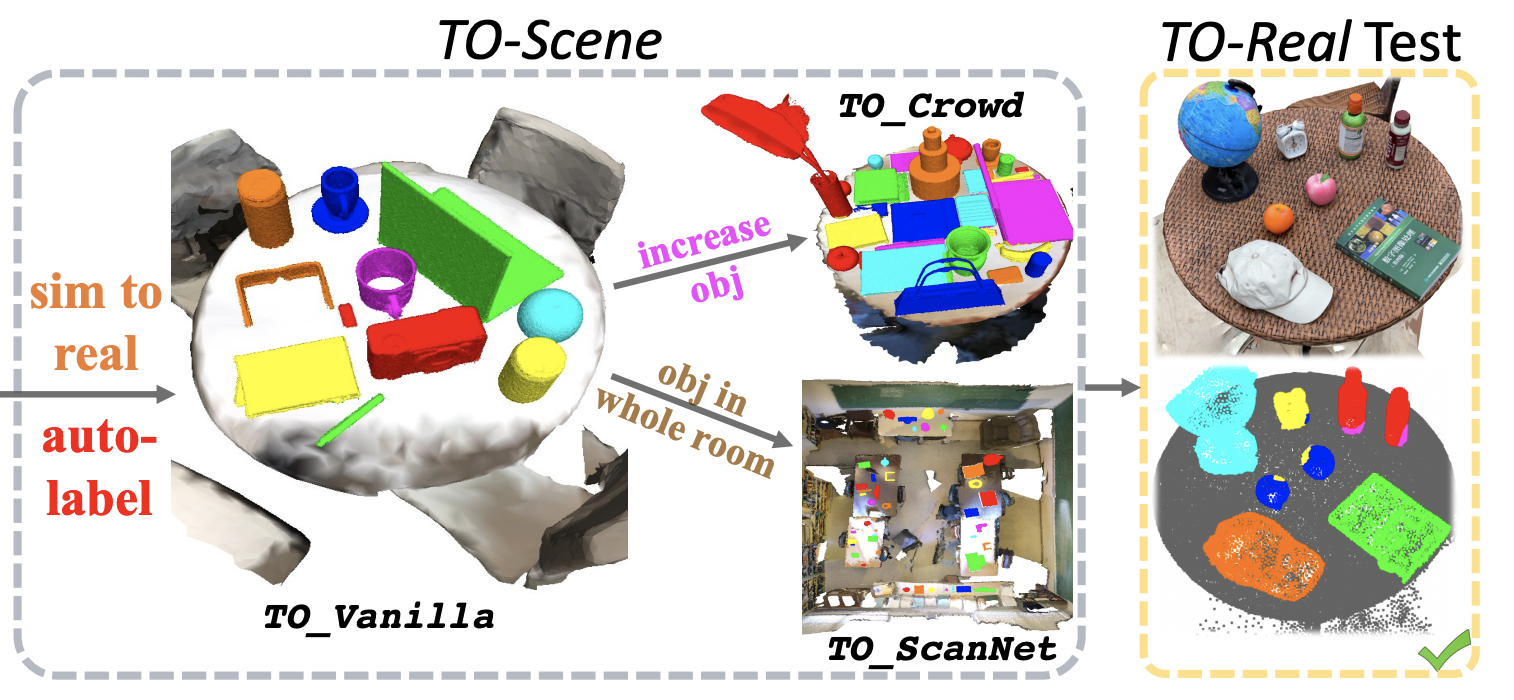
TO-Scene: A Large-scale Dataset for Understanding 3D Tabletop Scenes
Mutian Xu*, Yidan Zhang*, Haolin Liu, Xiaoguang Han†
European Conference on Computer Vision (ECCV), 2022, Oral Presentation
[paper] / [code]

Refer-it-in-RGBD: A Bottom-up Approach for 3D Visual Grounding in RGBD Images
Haolin Liu, Anran Lin, Xiaoguang Han†, Lei Yang, Yizhou Yu, Shuguang Cui
Computer Vision and Pattern Recognition Conference (CVPR), 2021
[paper] / [code]

JAFPro: Joint Appearance Fusion and Propagation for Human Video Motion Transfer from Multiple Reference Images
Xianggang Yu*, Haolin Liu*, Xiaoguang Han†, Zhen Li, Zixiang Xiong, Shuguang Cui
ACM International Conference on Multimedia (ACM MM), 2020
[paper] / [code]